With every webpage loaded, email sent, or video streamed, network traffic takes a complex journey…
Unfortunately for all involved, there was an extended Microsoft Office 365 outage in June 2016. Even more unfortunate given that it was the last day of the quarter. This outage affected US-based tenants and their email flow, though really for many Office 365 customers, the problem affected US multinational corporations throughout the world whose tenancy is US-based.
Exoprise customers affected by the issue were notified of the outage more than 2 hours before Microsoft reported the problem. These customers also had far more diagnostics and insight into the condition, its causes and potential workarounds. Many unaffected customers were still notified by Microsoft. Those with adequate coverage could confidently report to their CIOs they weren’t one of the unlucky. We’ll detail what we saw on our side and the experience our customers had.
Early Office 365 Outage Detection
CloudReady continuously monitors Office 365, Exchange and even Gmail mail queues. You can read more about how we do it here.
Our customers started receiving alarms that outbound mail processing was spiking at 8:30 am EST (12:30 pm UTC). This is the earliest anyone saw of a slowdown or issue with mail queue processing on Office 365. Customers with good coverage across their environment and good coverage across accounts (Exchange Online Protection vs regular Office 365) were also able to see the differences in inbound and outbound mail queue processing.
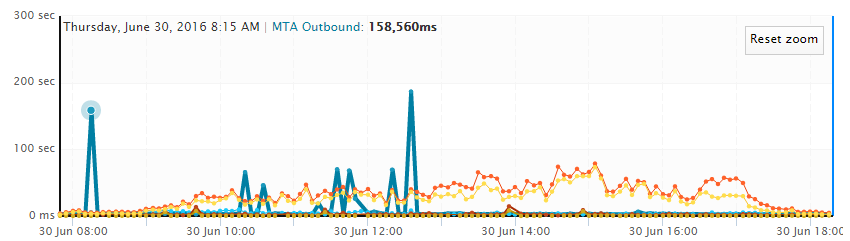
The Exoprise crowd data set (our specialty) really started to show increased mail queue delays starting at 9:00 am EST (1:00 pm UTC) and then started to get even more pronounced by 9:30-9:40 am (ugh, just as people were settling in for the last day of the quarter processing). One thing to point out in this chart is that the crowd data is aggregate and averaged so the values are spread across EOP affected customers and non-EOP affected customers. In short, the values and delays were higher then reported in this aggregate – mail was really delayed for most the afternoon in the US and we were finding email that was completely rejected as the EOP servers were unable to keep with the connection flow, retries and lack of capacity. Our simple synthetic test mails were round tripping in upwards of 5-10 minutes when they normally round-trip in under 10 seconds (a 60x slowdown).
What Customer Dashboards Started to Look Like
Our customers started logging in furiously. We also have Office 365 Portal sensors that monitor the up-time of the Office 365 administrative portal and those sensors started firing timeout errors. That’s usually a decent indicator that there’s a bigger problem at hand.
First Indications from Microsoft
Houston, we have a problem. Microsoft’s first report of the problem through their Online Portal, service status feed (Office 365 Management Pack), or mobile admin application was 11:12 AM EST. That’s about 2 hours after CloudReady first noticed slowdowns and about 2 hours after most of our customers started to experience significant alarms and warnings from CloudReady. Here’s the incident status.
Investigating – Jun 30, 2016 11:12 AM
Current Status: We’re investigating an issue in which some users may be unable to access or use Exchange Online Protection services or features. We’ll provide an update shortly.
User Impact: Users may be experiencing delays when sending email messages.
Scope of Impact: A few customers have reported this issue, and we’re checking for potential impact to your users
Then the messages started to get more ominous about the outage and impact to customers.
Service degradation – Jun 30, 2016 11:45 AM
Current Status: We’re analyzing the affected infrastructure to determine the root cause and formulate a remediation plan.
User Impact: Users are experiencing delays when sending and receiving email messages. Affected users are receiving Non-Delivery Reports (NDR) when sending email messages.
Scope of Impact: Customer reports indicate that many users will likely experience impact related to this event. Our analysis indicates that impact is specific to a subset of users who are served through the affected infrastructure.
Start Time: Thursday, June 30, 2016, at 2:30 PM UTC
Basically, inbound and outbound email started to have serious problems and mail queues were filling up. Here at Exoprise we noticed that customers that were not on Exchange Online Protection (EOP) were not having the problem. So, clearly it was a problem with the more advanced Exchange Online Protection.
Some of our customers have sensors on both regular mail protection from Office 365 and some sensors on EOP. For those customers they noticed a difference and could route important email to the right accounts if they had to for the emergency. Honestly, Exoprise hasn’t seen this kind of outage before and now we will recommend that customers split their sensors (where possible) for coverage across both protection environments.
And Then It Just Went On and On
The Office 365 outage in June 2016 persisted for some time, more then 6 hours for some customers and certainly longer then anyone would like. Mail queues performance finally started to stabilize and imprve at 5:20 PM EST (9:20 PM UTC). This is according to the CloudReady crowd data which every customer has access to in real-time.
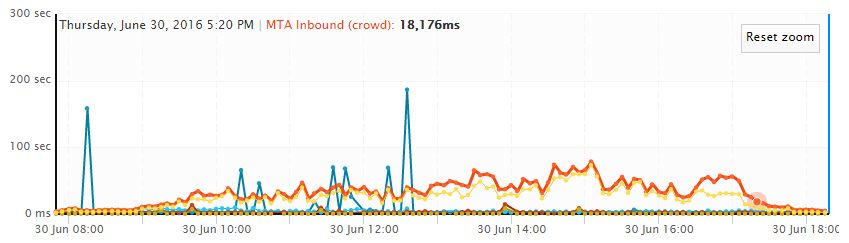
The interesting thing to note here about the messages from Microsoft and their Service Communications API is that they were telling customers that they had it under control earlier and that they had expected things to improve. For example:
Restoring service – Jun 30, 2016 1:23 PM
Current Status: We’ve completed the process of restarting services and are shifting traffic to a healthy portion of the infrastructure to reduce impact. In parallel, we’re reverting a recent update which may have caused the service to operate below the expected threshold.
User Impact: Users are experiencing delays when sending and receiving email messages. Affected users will receive Non-Delivery Reports (NDR) when sending email messages.
Scope of Impact: Customer reports indicate that many users will likely experience impact related to this event. Our analysis indicates that impact is specific to a subset of users who are served through the affected infrastructure.
There were really wasn’t any improvement for another few hours according to our data. This is often the case with cloud provider status communications — providers report that a fix is underway for everyone but no-one knows when it will recover for them.
Benefits of CloudReady
While these kinds of widespread incidents are rare, they are not the only kind of incidents that affect your users. Problems don’t only occur in the SaaS provider’s network or software; they can happen anywhere in the end-to-end equation, and if they start from within your own infrastructure, network, or its connection through your ISP to the cloud, you won’t be getting any notification from Microsoft.
The unfortunate truth is that service degradation happens for a variety of reasons and can do real damage if it hits at an important time like the last day of the quarter. Only by monitoring the end-to-end service health with a tool like CloudReady, can you assure that, next time, you’ll be in a position to recognize the problem and take action before your users even start reporting problems.
That’s why so many organizations using Office 365 and other cloud services rely on Exoprise for best in class service monitoring and alerting. Just like the Office 365 outage in June 2016, more can happen. Let us cover your SaaS, give it a try.
Related Posts


